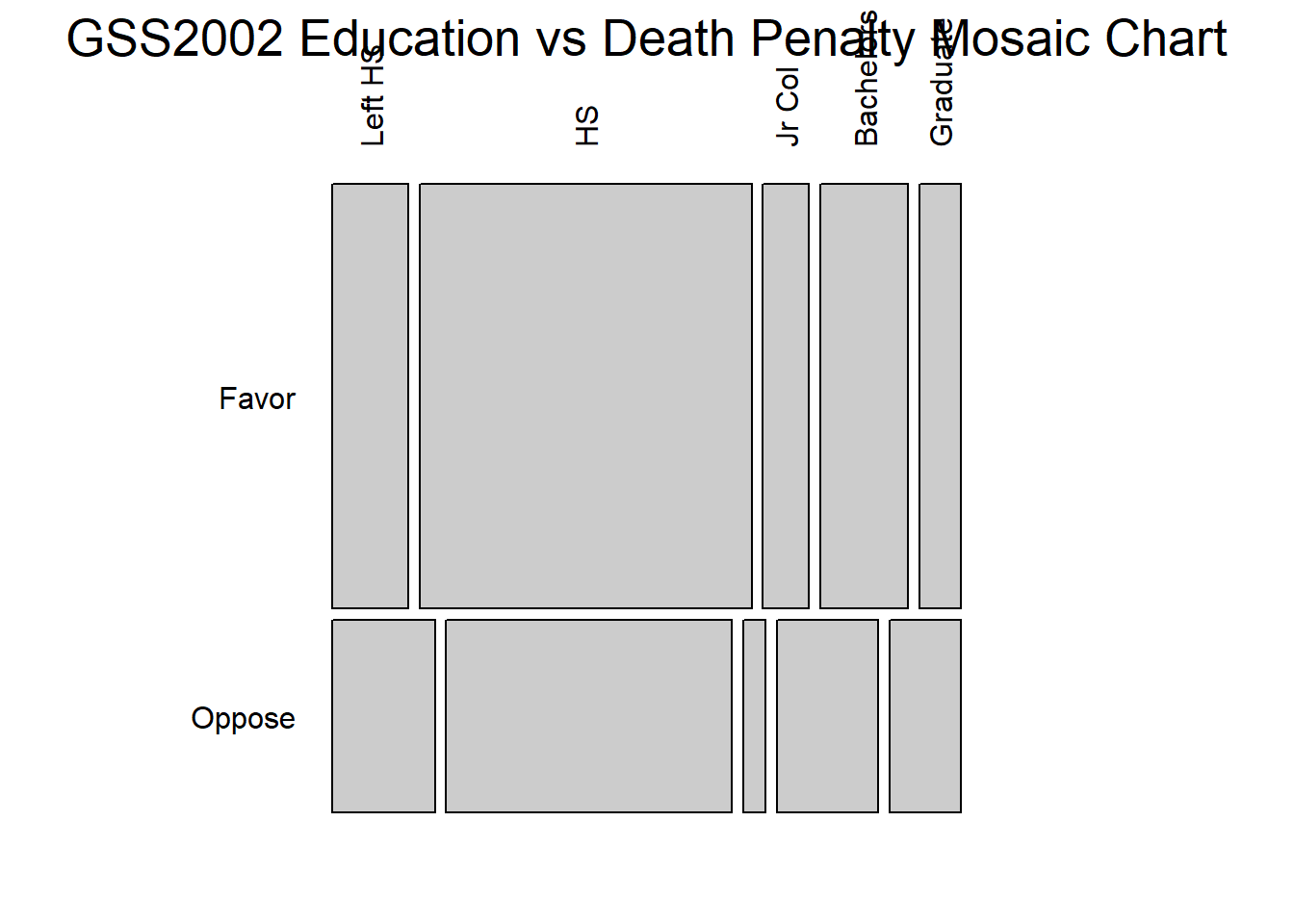
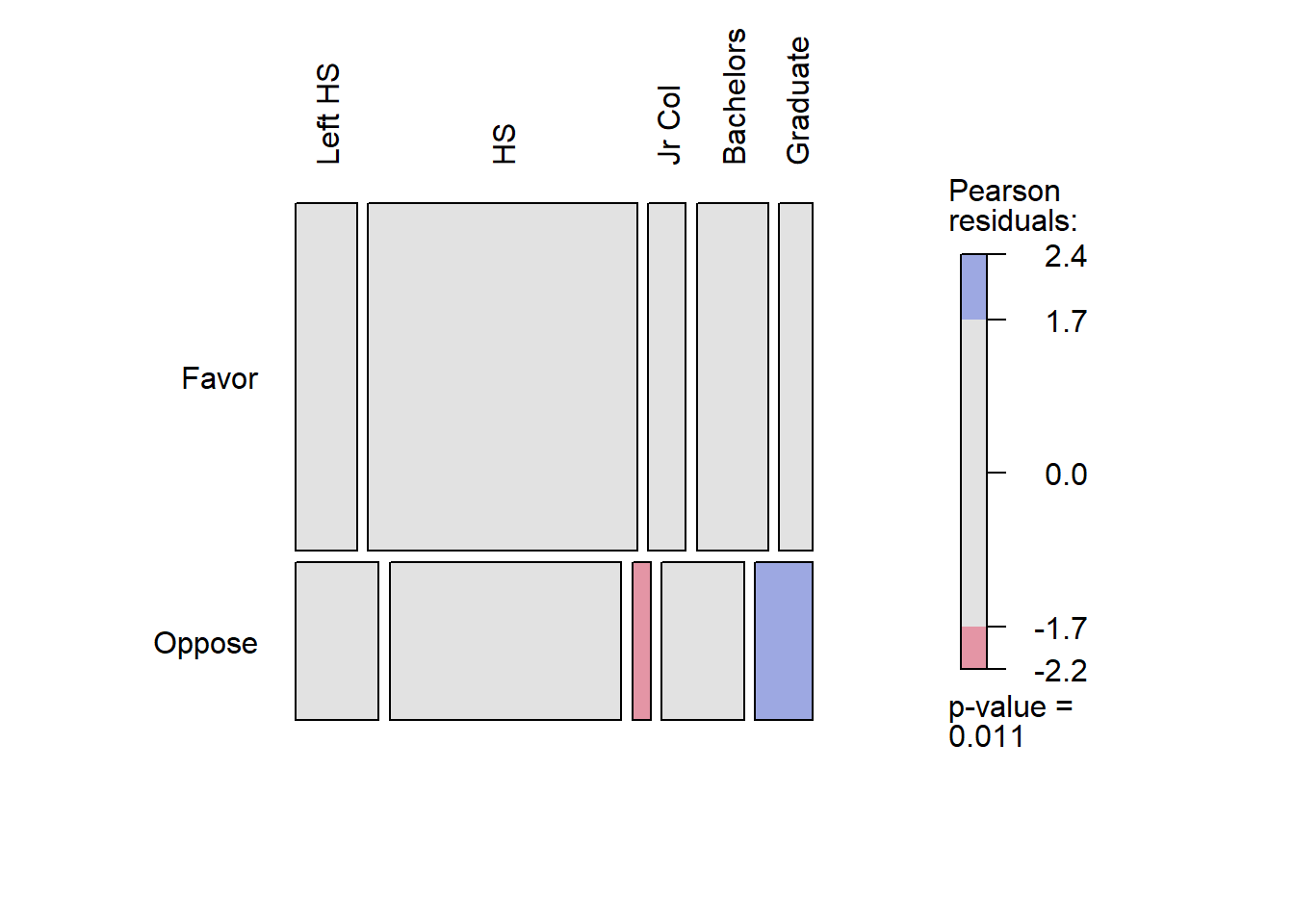
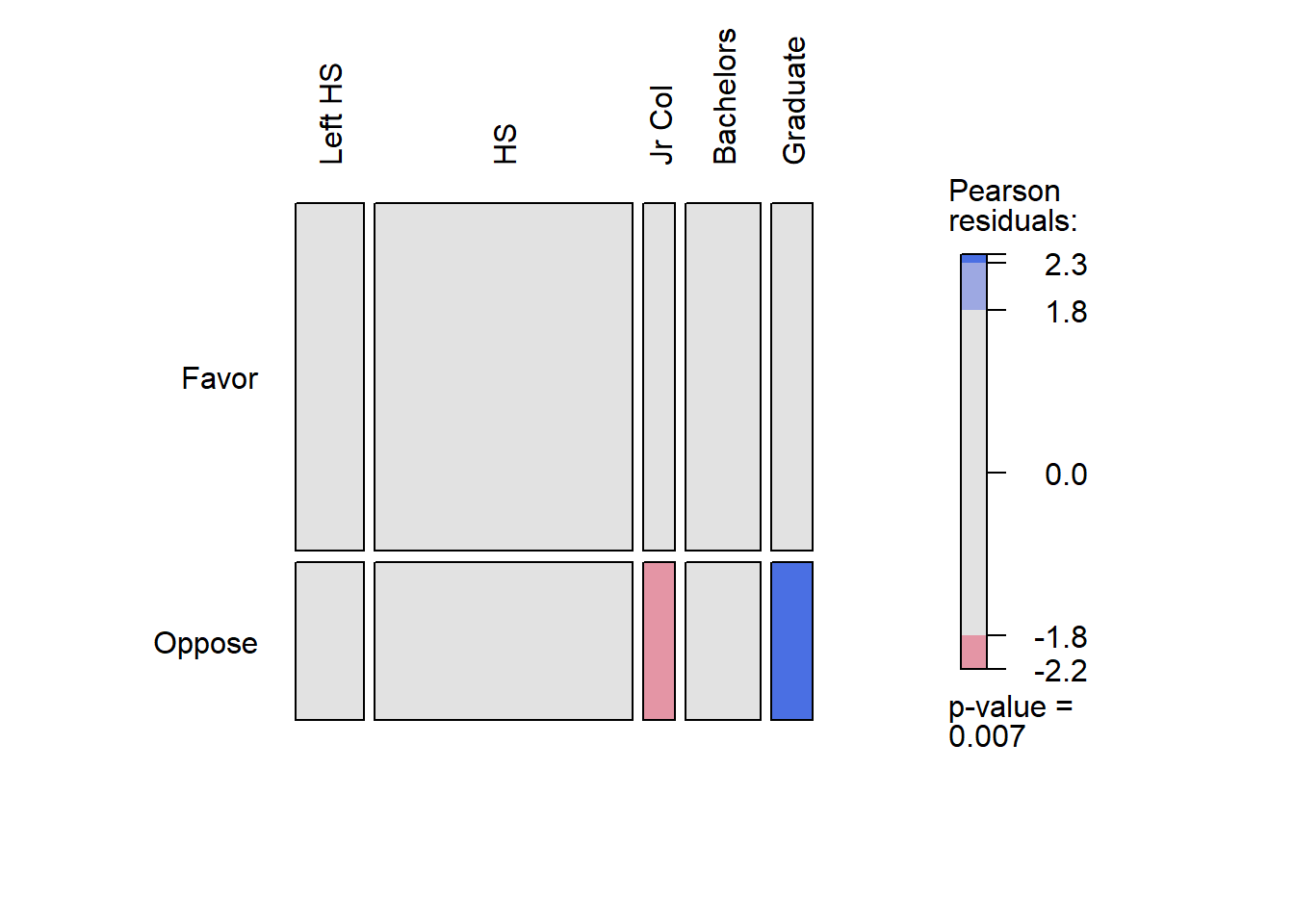
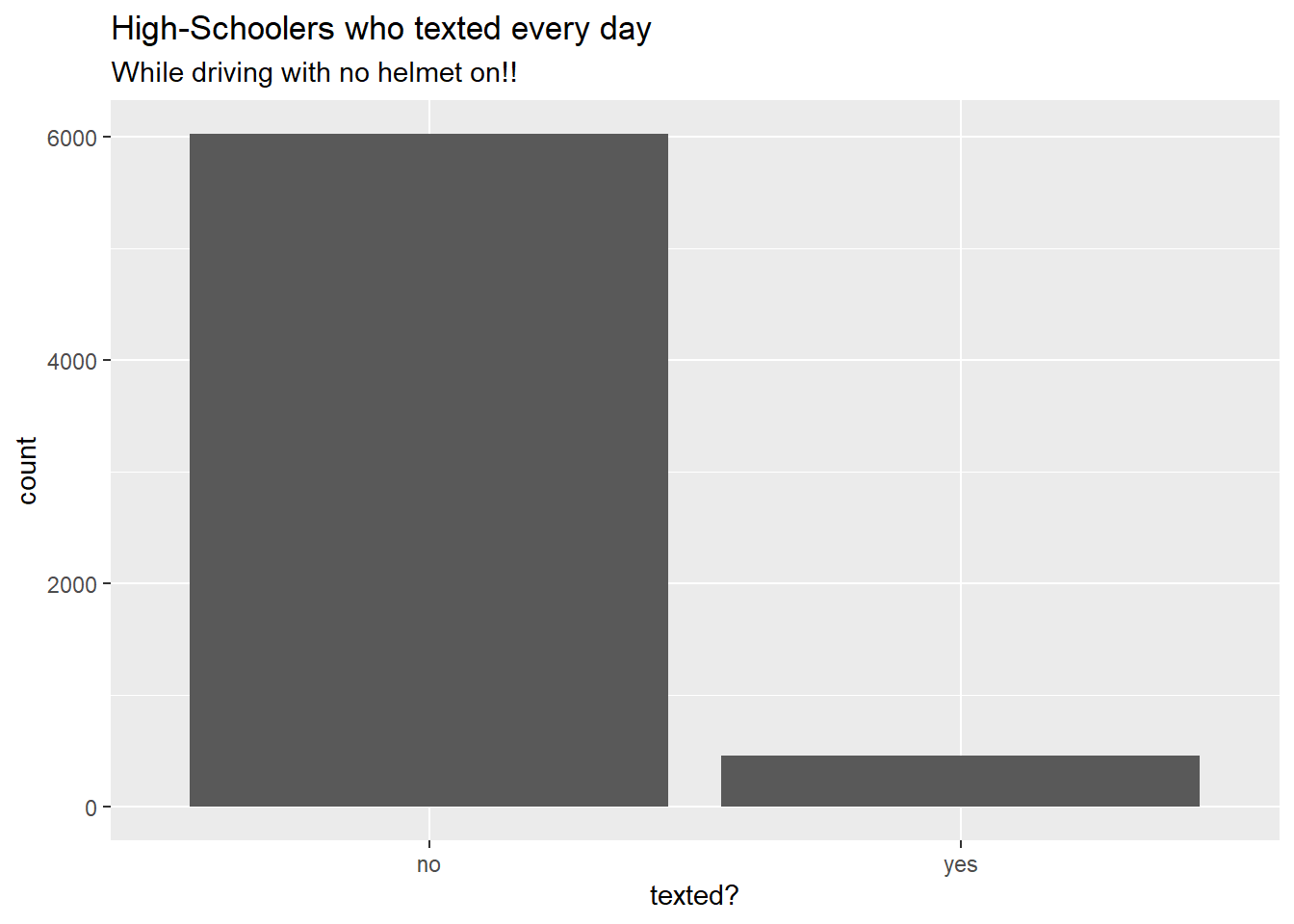Rows: 2,765
Columns: 21
$ ID <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
$ Region <fct> South Central, South Central, South Central, South Centr…
$ Gender <fct> Female, Male, Female, Female, Male, Male, Female, Female…
$ Race <fct> White, White, White, White, White, White, White, White, …
$ Education <fct> HS, Bachelors, HS, Left HS, Left HS, HS, Bachelors, HS, …
$ Marital <fct> Divorced, Married, Separated, Divorced, Divorced, Divorc…
$ Religion <fct> Inter-nondenominational, Protestant, Protestant, Protest…
$ Happy <fct> Pretty happy, Pretty happy, NA, NA, NA, Pretty happy, NA…
$ Income <fct> 30000-34999, 75000-89999, 35000-39999, 50000-59999, 4000…
$ PolParty <fct> "Strong Rep", "Not Str Rep", "Strong Rep", "Ind, Near De…
$ Politics <fct> Conservative, Conservative, NA, NA, NA, Conservative, NA…
$ Marijuana <fct> NA, Not legal, NA, NA, NA, NA, NA, NA, Legal, NA, NA, NA…
$ DeathPenalty <fct> Favor, Favor, NA, NA, NA, Favor, NA, NA, Favor, NA, NA, …
$ OwnGun <fct> No, Yes, NA, NA, NA, Yes, NA, NA, Yes, NA, NA, NA, NA, N…
$ GunLaw <fct> Favor, Oppose, NA, NA, NA, Oppose, NA, NA, Oppose, NA, N…
$ SpendMilitary <fct> Too little, About right, NA, About right, NA, Too little…
$ SpendEduc <fct> Too little, Too little, NA, Too little, NA, Too little, …
$ SpendEnv <fct> About right, About right, NA, Too little, NA, Too little…
$ SpendSci <fct> About right, About right, NA, Too little, NA, Too little…
$ Pres00 <fct> Bush, Bush, Bush, NA, NA, Bush, Bush, Bush, Bush, NA, NA…
$ Postlife <fct> Yes, Yes, NA, NA, NA, Yes, NA, NA, Yes, NA, NA, NA, NA, …