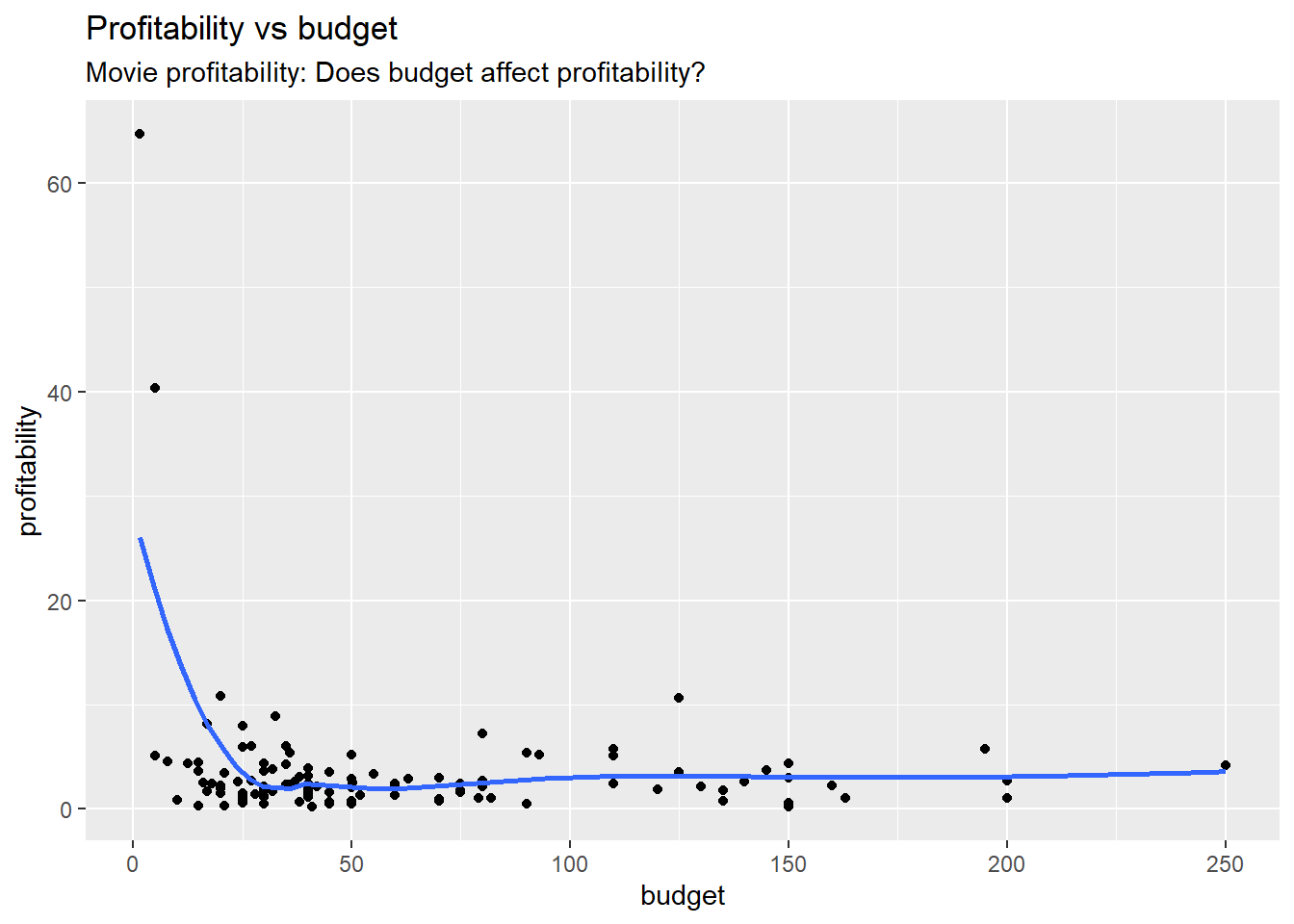
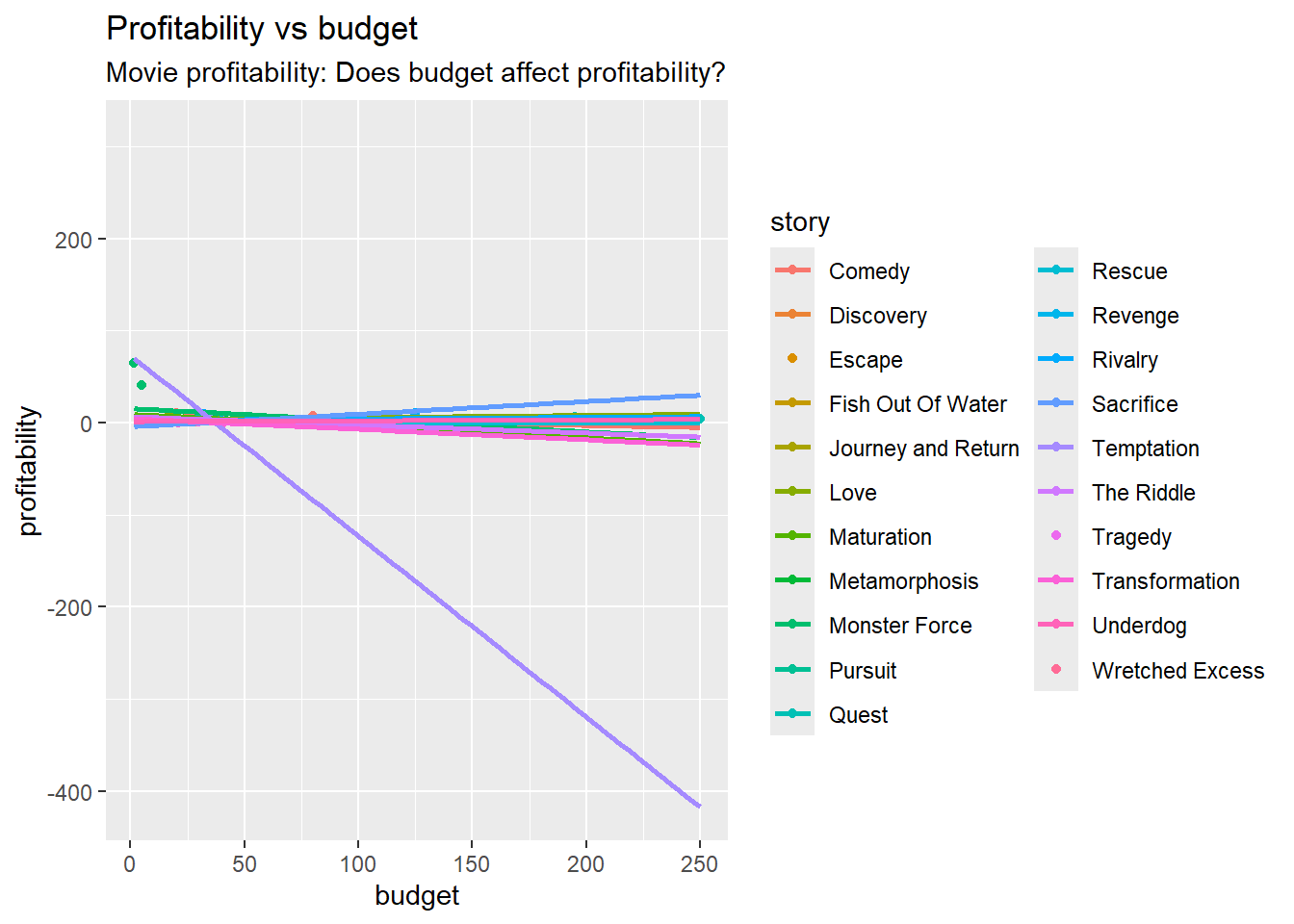
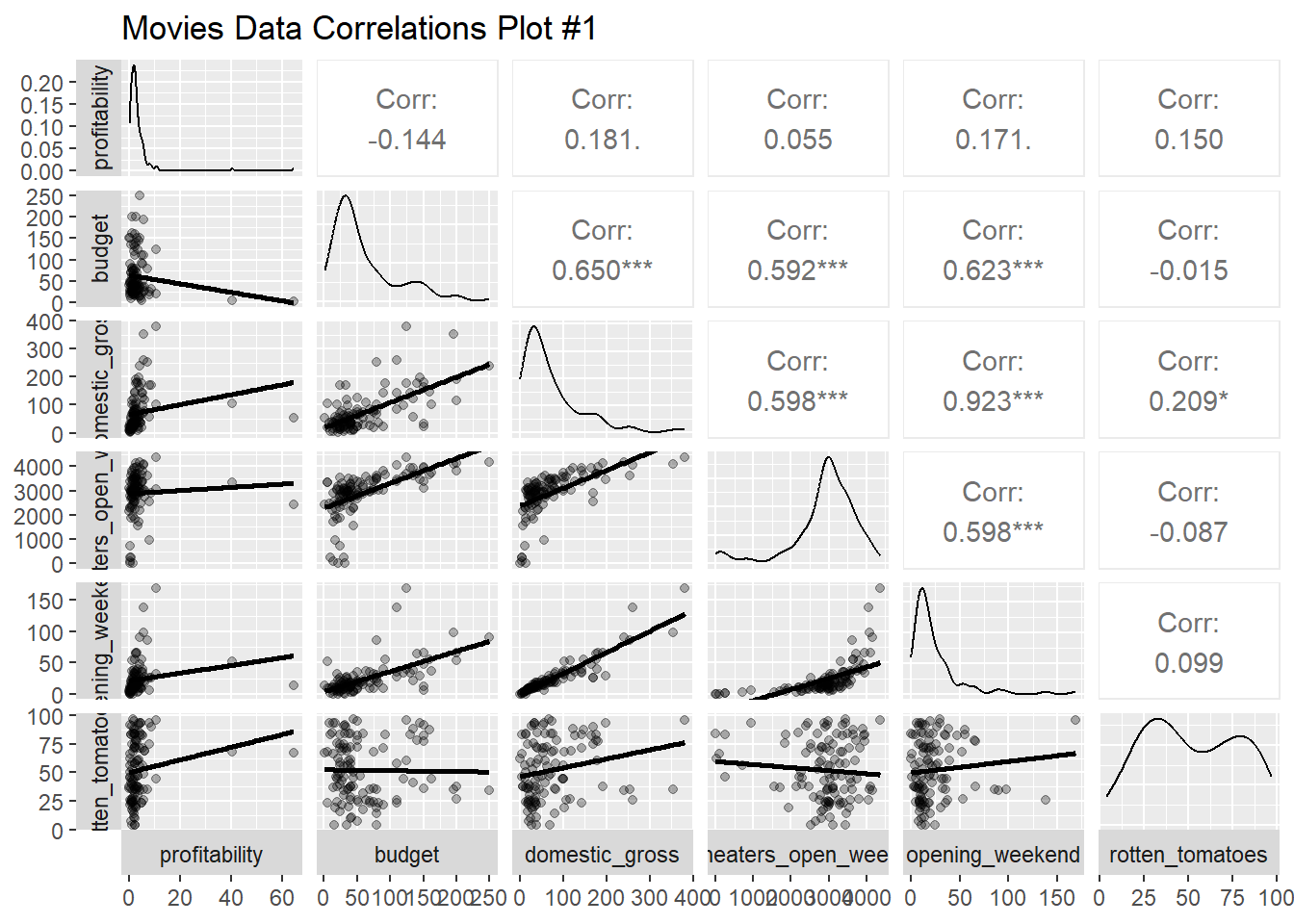
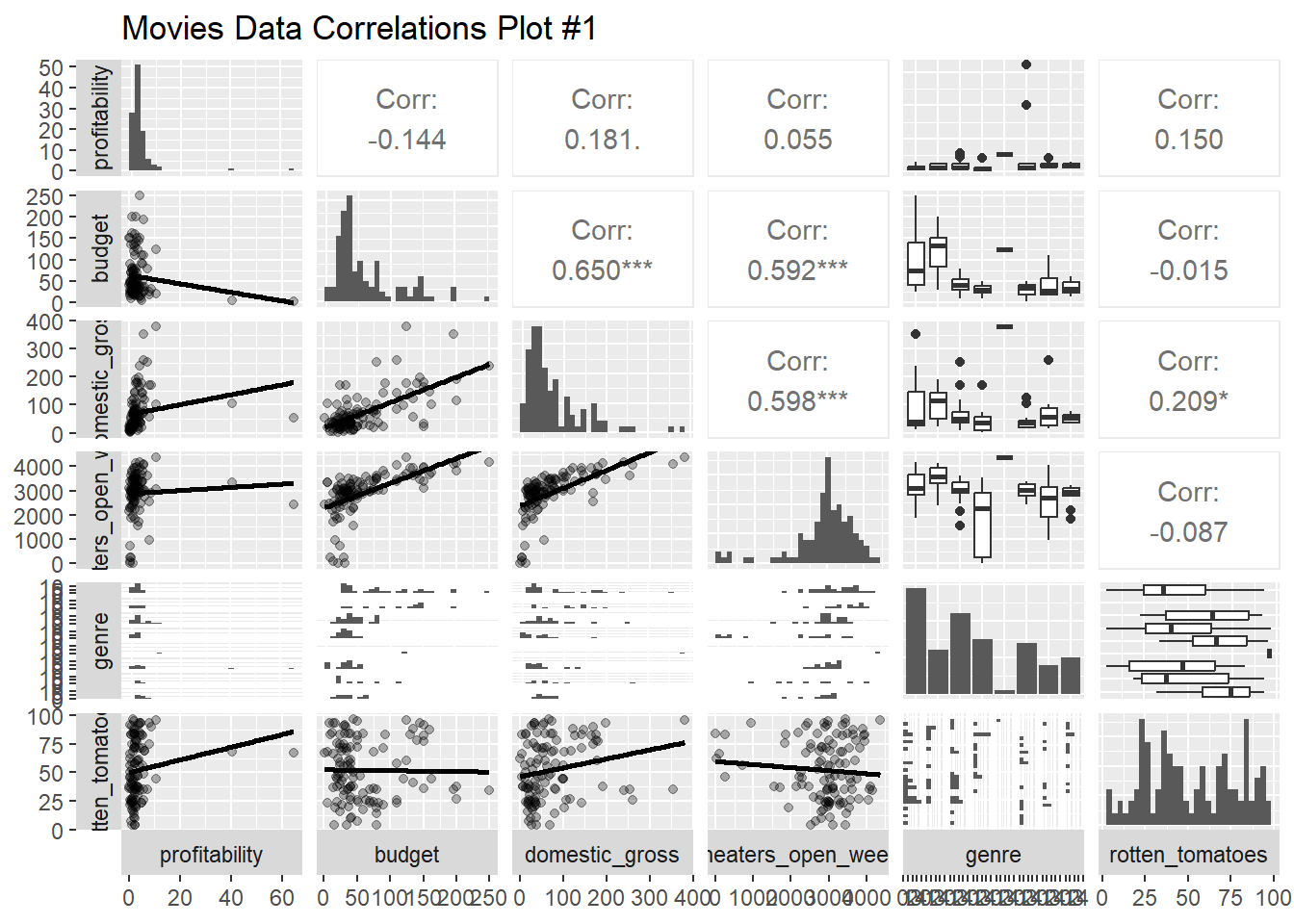
library(tidyverse) # Tidy data processing and plotting
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.1.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(ggformula)# Formula based plots
Loading required package: scales
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
Loading required package: ggridges
New to ggformula? Try the tutorials:
learnr::run_tutorial("introduction", package = "ggformula")
learnr::run_tutorial("refining", package = "ggformula")
Registered S3 method overwritten by 'mosaic':
method from
fortify.SpatialPolygonsDataFrame ggplot2
The 'mosaic' package masks several functions from core packages in order to add
additional features. The original behavior of these functions should not be affected by this.
Attaching package: 'mosaic'
The following object is masked from 'package:Matrix':
mean
The following object is masked from 'package:scales':
rescale
The following objects are masked from 'package:dplyr':
count, do, tally
The following object is masked from 'package:purrr':
cross
The following object is masked from 'package:ggplot2':
stat
The following objects are masked from 'package:stats':
binom.test, cor, cor.test, cov, fivenum, IQR, median, prop.test,
quantile, sd, t.test, var
The following objects are masked from 'package:base':
max, mean, min, prod, range, sample, sum
library(skimr) # Another Data inspection package
Attaching package: 'skimr'
The following object is masked from 'package:mosaic':
n_missing
library(GGally) # Corr plotslibrary(broom) # Clean reports from Stats / ML outputs# library(devtools)# devtools::install_github("rpruim/Lock5withR")library(Lock5withR) # Datasetslibrary(easystats) # Easy Statistical Analysis and Charts
library(correlation) # Different Types of Correlationslibrary(janitor) # Data cleaning and tidying package
Attaching package: 'janitor'
The following object is masked from 'package:insight':
clean_names
The following objects are masked from 'package:datawizard':
remove_empty, remove_empty_rows
The following objects are masked from 'package:stats':
chisq.test, fisher.test
library(visdat) # Visualize whole dataframes for missing datalibrary(naniar) # Clean missing data
Attaching package: 'naniar'
The following object is masked from 'package:skimr':
n_complete
library(DT) # Interactive Tables for our datalibrary(tinytable) # Elegant Tables for our data
Attaching package: 'tinytable'
The following object is masked from 'package:ggplot2':
theme_void
library(ggrepel) # Repelled Text Labels in ggplotlibrary(marquee) # Marquee Text Labels in ggplotlibrary(dplyr)
lead_studio n
1 Aardman Animations 1
2 CBS Films 1
3 DreamWorks Animation 1
4 Happy Madison Productions 1
5 Miramax Films 1
6 Morgan Creek Productions 1
7 New Line Cinema 1
8 Pixar 1
9 Regency Enterprises 1
10 Relativity 1
11 Reliance Entertainment 1
12 Sony Pictures Animation 1
13 Vertigo Entertainment 1
14 Village Roadshow Pictures 1
15 Virgin 1
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.
mosaic::cor_test(domestic_gross ~ budget, data = movies_modified) %>% broom::tidy() %>% knitr::kable(digits =2,caption ="Movie Domestic Gross vs budget" )